
We present Vid2Avatar, a method to learn human avatars from monocular in-the-wild videos. Reconstructing humans that move naturally from monocular in-the-wild videos is difficult. Solving it requires accurately separating humans from arbitrary backgrounds. Moreover, it requires reconstructing detailed 3D surface from short video sequences, making it even more challenging. Despite these challenges, our method does not require any groundtruth supervision or priors extracted from large datasets of clothed human scans, nor do we rely on any external segmentation modules. Instead, it solves the tasks of scene decomposition and surface reconstruction directly in 3D by modeling both the human and the background in the scene jointly, parameterized via two separate neural fields. Specifically, we define a temporally consistent human representation in canonical space and formulate a global optimization over the background model, the canonical human shape and texture, and per-frame human pose parameters. A coarse-to-fine sampling strategy for volume rendering and novel objectives are introduced for a clean separation of dynamic human and static background, yielding detailed and robust 3D human geometry reconstructions. We evaluate our methods on publicly available datasets and show improvements over prior art.
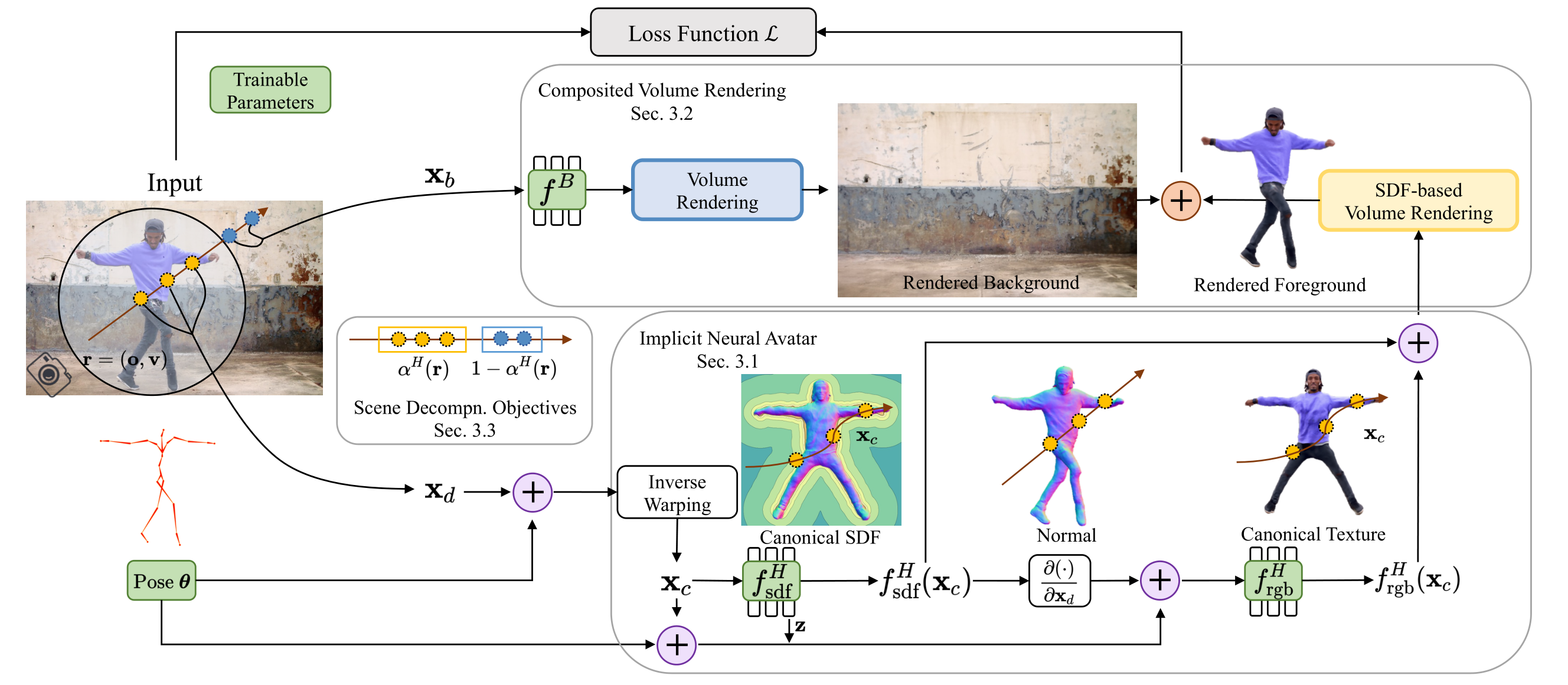
To reconstruct detailed geometry and appearance of the implicit neural avatars from monocular videos in the wild, we solve the tasks of scene decomposition and surface reconstrution directly in 3D in contrast to prior works that utilize off-the-shelf 2D segmentation tools or manually labeled masks. To achieve this, we model both the human and background in the scene implicitly, parametrized via two separate neural fields which are learned jointly from images to composite the whole scene. To alleviate the ambiguity of in-contact body and scene parts and to better delineate the surfaces, we contribute novel objectives that leverage the dynamically updated human shape in canonical space to regularize the ray opacity.
Our approach outperforms existing state-of-the-art methods due to the superiority of our method to the better decoupling of humans from the background vis self-supervised scene decomposition.
Our method can generalize to different human shapes, garment styles and facial features even under challenging poses and complicated environments.
The reconstructed 3D avatar can be viewed from any angle.
We create a new dataset called SynWild to evaluate the human surface reconstruction from monocular videos in the wild. Dynamic human subjects are captured in a dense multi-view system and reconstructed with detailed surface geometry and realistic textures via commercial software. Then we place the textured 4D scans into realistic 3D scenes/HDRI panoramas and render monocular videos from virtual cameras with a 35mm focal length and 1920x1080 image resolution, leveraging Unreal engine. In total, this dataset includes 6 video sequences (1091 frames) with different motions, human subjects, and backgrounds. This is the first dataset that allows for quantitative comparison of monocular human reconstruction in a realistic setting via semi-synthetic data. Please fill out the SynWild Application Form to access SynWild dataset. We will send you an email with more information after approval of your application.
Chen Guo was supported by Microsoft Research Swiss JRC Grant. Xu Chen was supported by the Max Planck ETH Center for Learning Systems. We thank Manuel Kaufmann and Juan Zarate for proofreading. We also thank Doriano van Essen for helping us with the SynWild dataset. We sincerely thank Marquese Scott for his amazing dancing videos!
@inproceedings{guo2023vid2avatar,
title={Vid2Avatar: 3D Avatar Reconstruction from Videos in the Wild via Self-supervised Scene Decomposition},
author={Guo, Chen and Jiang, Tianjian and Chen, Xu and Song, Jie and Hilliges, Otmar},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023},
}