
While previous years have seen great progress in the 3D reconstruction of humans from monocular videos, few of the state-of-the-art methods are able to handle loose garments that exhibit large non-rigid surface deformations during articulation. This limits the application of such methods to humans that are dressed in standard pants or T-shirts. We present ReLoo , a novel method that overcomes this limitation and reconstructs high-quality 3D models of humans dressed in loose garments from monocular in-the-wild videos. To tackle this problem, we first establish a layered neural human representation that decomposes clothed humans into a neural inner body and outer clothing. On top of the layered neural representation, we further introduce a non-hierarchical virtual bone deformation module for the clothing layer that can freely move, which allows the accurate recovery of non-rigidly deforming loose clothing. A global optimization is formulated that jointly optimizes the shape, appearance, and deformations of both the human body and clothing over the entire sequence via multi-layer differentiable volume rendering. To evaluate ReLoo, we record subjects with dynamically deforming garments in a multi-view capture studio. The evaluation of our method, both on existing and our novel dataset, demonstrates its clear superiority over prior art on both indoor datasets and in-the-wild videos.
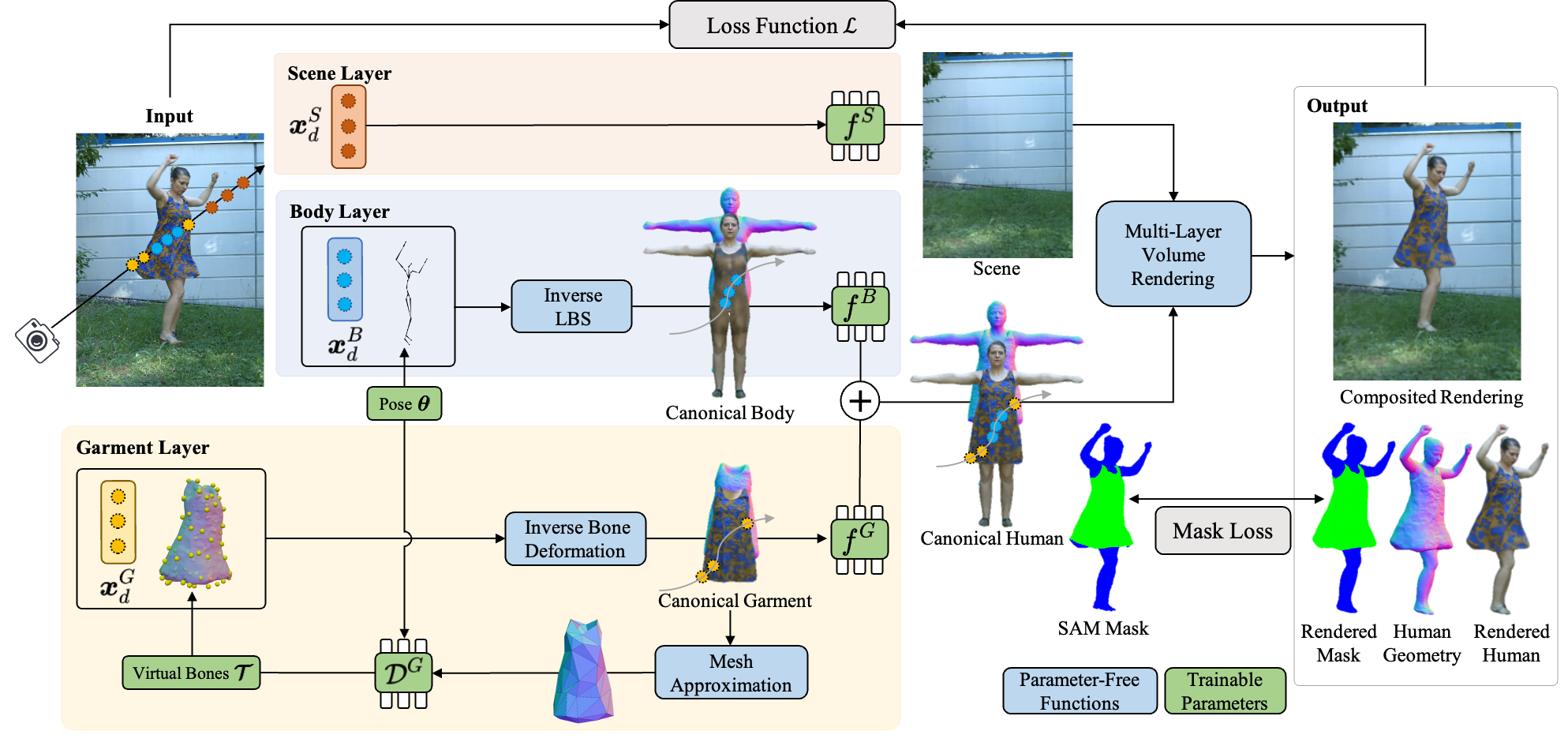
Given an image from a video sequence, we sample points along the camera ray for each neural layer. We warp sampled points for the body layer into canonical space via inverse LBS derived from skeletal deformations. We deform sampled points for the garment layer into canonical space via inverse warping based on the proposed virtual bone deformation module. We then evaluate the respective implicit network to obtain the SDF and radiance values. We apply multi-layer differentiable volume rendering to learn the shape, appearance, and deformations of the layered neural human representation from images. The loss function compares the rendered color predictions with image observations as well as a segmentation mask obtained using SAM.
In order to evaluate the generalization of our method to diverse garment styles, we collect a dataset called MonoLoose with clothed dynamic human subjects captured in a dense multi-view system. It contains five sequences of humans dressed in loose garments in each sequence. Half of the sequences are captured in the stage with ground truth annotations for quantitative evaluation and the others are captured in the wild for qualitative evaluation. More details and the download link for the dataset will be available soon.
This work was partially supported by the Swiss SERI Consolidation Grant "AI-PERCEIVE". Chen Guo was partially supported by Microsoft Research Swiss JRC Grant. We thank Juan Zarate for proofreading and insightful discussion. We also want to express our gratitude to participants of our dataset. We use AITViewer for 2D/3D visualizations. All experiments were performed on the ETH Zürich Euler cluster.
@inproceedings{reloo,
title={ReLoo: Reconstructing Humans Dressed in Loose Garments from Monocular Video in the Wild},
author={Guo, Chen and Jiang, Tianjian and Kaufmann, Manuel and Zheng, Chengwei and Valentin, Julien and Song, Jie and Hilliges, Otmar},
booktitle={European conference on computer vision (ECCV)},
year={2024},
}